


Сегодня хочу поговорить с вами о предотвращении индексации от Googlebot для определенных страниц. Это необходимо для того, чтобы скрыть от поисковой системы страницы, которые не следует ей показывать, или же наоборот показать, какие страницы нужно проиндексировать.
Вообще есть четыре правила, которые запрещают индексацию определенных страниц:
- Robots.txt
- <Meta name = «robots» content = «noindex, nofollow»>
- X-Robots-Tag noindex, nofollow
- Canonical
Как закрыть индексацию страницы от поисковых систем через Robots.txt?s
Это основной файл, который Google ищет в первую очередь, то есть сразу после попадания на сайт. Именно он должен сообщить поисковой системе, куда ей можно или нельзя заходить. В первую очередь в нем следует указать весь контент, который вы планируете скрыть от поисковых систем.
К примеру, на нашем сайте https://plerdy.com/robots.txt не было причин ничего закрывать. У нас около трех сотен страниц, однако нет потенциальных дублей, фильтраций, которые нужно было бы закрывать. Это более необходимо для Интернет-магазинов, например, сайт https://www.foxtrot.com.ua/robots.txt имеет уже достаточно много закрытых страниц, хотя много есть и разрешенных. При этом есть моменты, особенно в таких CMS-системах, как magento и opencart, где присутствуют десятки строк, которые стоит закрывать.
Кроме этого Robots.txt помогает, если у вас проблемы с сервером, а Googlebot пытается сканировать страницы. В этом случае обязательно закрывайте Robots.txt и нагрузка может упасть. Это, конечно, можно делать другими способами.
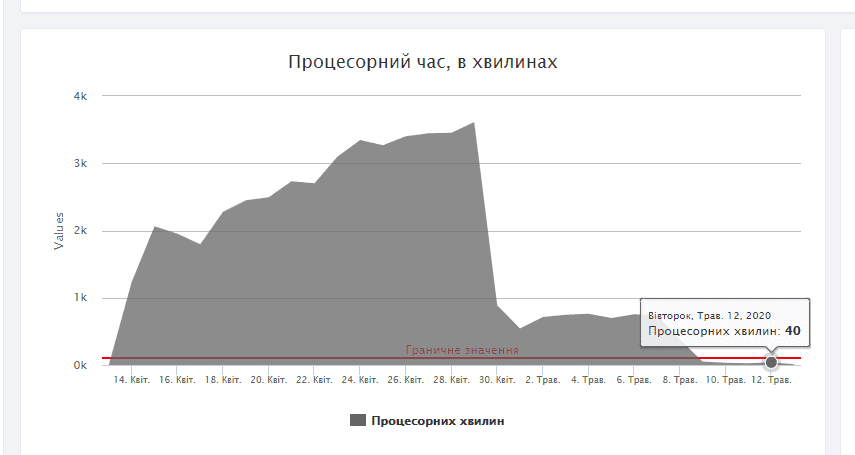
Я показываю вам пример, когда было сделано уменьшение количества автоматических запросов от Googlebot в день с 8 до 3. Это позволило не индексировать лишние страницы и решить проблему.
Вы можете увидеть, как настраивать страницы Robots.txt здесь.
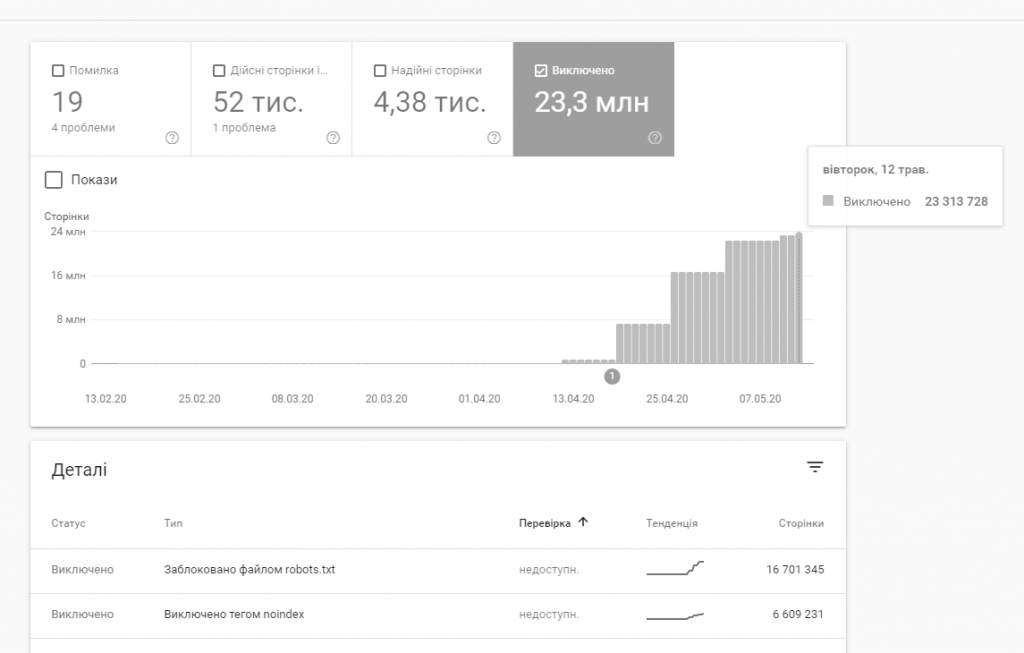
Это пример, когда Googlebot делал попытки индексировать очень много страниц. Часть из них закрыта с помощью Robots.txt, часть из noindex.
Как закрыть индексацию страницы от поисковых систем с помощью <meta name = «robots» content = «noindex, nofollow»>
При использовании второго и третьего способов закрытия страниц (<meta name = «robots» content = «noindex, nofollow»> и X-Robots-Tag noindex, nofollow) Googlebot вынужден зайти на страницу и только после этого сказать, что не будет ее индексировать.
Как закрыть индексацию страницы от поисковых систем с помощью X-Robots-Tag noindex, nofollow
Третий способ не является эффективным для уменьшения количества индексации и запросов, то есть они не появятся в поиске, но Google будет делать попытки зайти на них. Кроме этого он является наиболее редким, но Google его поддерживает. Если говорить о моей личной практике, то примерно за 10 лет, я использовал его всего один раз.
Canonical, как еще один способ борьбы с контентом, что дублируется
Если у вас есть ссылки с GET-параметрами и они также являются дублями, тогда следует ставить там Canonical. Если же его поставить на обычной ссылке, тогда Google может игнорировать его и продолжать индексацию. Такое случается довольно часто. Желательно таких моментов избегать, хотя критического в этом ничего нет.
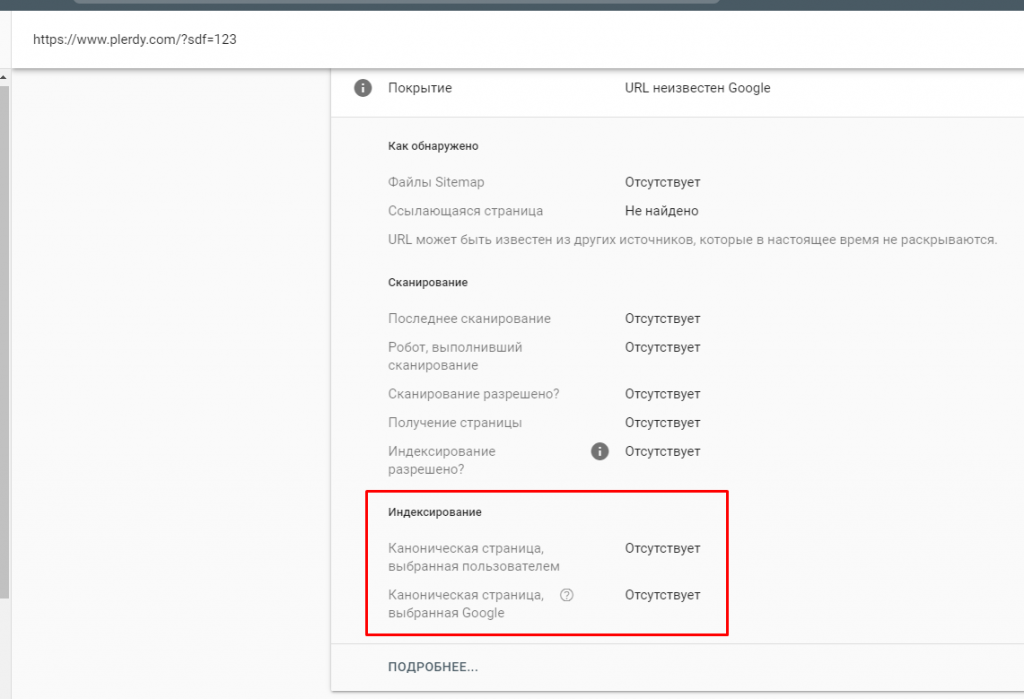
Как видите на примере, если страница является не проиндексирована, то Canonical показывать не будет. То есть, она должна быть проиндексированной, чтобы Google это увидел и это важно.
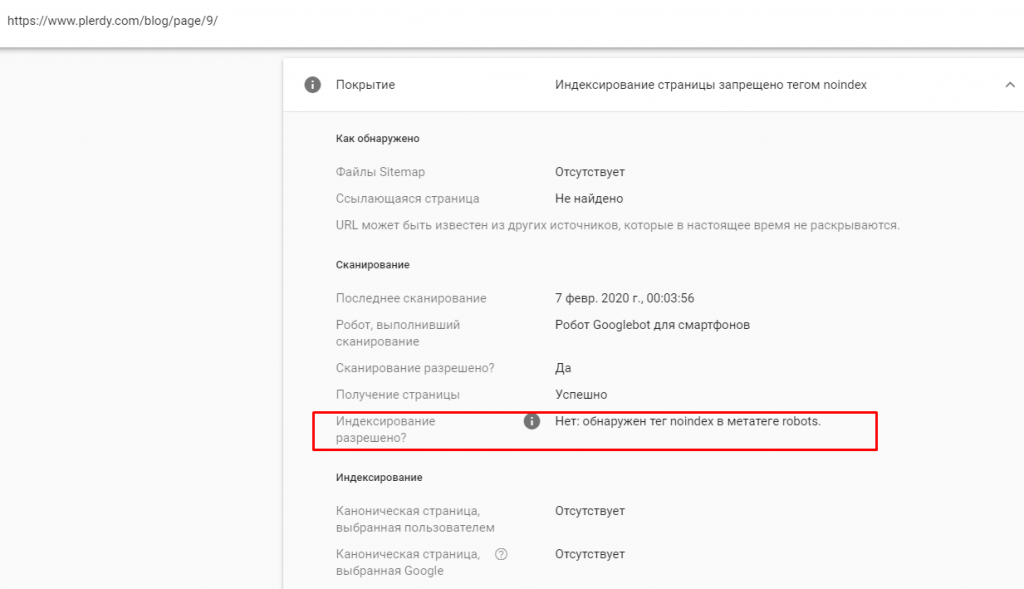
Еще один важный момент — когда страница заблокирована, она будет давать разрешение индексировать, но запрещать показывать ее поисковой системе. Если же она заблокирована в Robots.txt, то в графе о разрешении на индексацию будет стоять — нет.
Микширования этих способов закрытия страницы от индексации в поисковых системах
Следует избегать микширования всех этих способов или определенных из них. Это не под строгим запретом и вы не получите санкций, но специалисты от Google говорят, что стоит все-таки избегать этого. Хотя я лично видел много примеров, где все находится на одной и той же странице.
Если вы хотите проверить, добавить определенные ссылки или убрать, то для этого есть тестирование файла Robots.txt. Там можно добавить любое правило, пересмотреть инструкцию и сделать все правильно, чтобы случайно не заблокировать страницу, которая является востребованной. В этой инструкции указано, что файл Robots.txt не является обязательным, но, по моему мнению, он обязателен. Благодаря ему решается немало вопросов, особенно, если речь о больших интернет-магазинах.
Эти основные правила, которые я озвучил, обязательно следует настраивать перед запуском сайта, а также следить в процессе по всем страницам, чтобы четко понимать, как и куда ходит Google. В общем все, если у вас остались вопросы, обязательно задавайте их в комментариях. Ставьте лайки и подписывайтесь на мой канал, здесь будет еще много интересного.

 (2 оценок, среднее: 3,00 из 5)
(2 оценок, среднее: 3,00 из 5) Как избежать блокировок рекламного кабинета Facebook (Meta) с помощью правильных IP
Как избежать блокировок рекламного кабинета Facebook (Meta) с помощью правильных IP Карта кликов сайта: обзор 16 сервисов
Карта кликов сайта: обзор 16 сервисов Продвижение сайтов
Продвижение сайтов Бесплатная раскрутка сайта в Google: 20 советов
Бесплатная раскрутка сайта в Google: 20 советов Продвижение интернет-магазина
Продвижение интернет-магазина Продвижение сайта в ТОП-10 Google
Продвижение сайта в ТОП-10 Google Контекстная реклама сайта в Google: 27 ошибок
Контекстная реклама сайта в Google: 27 ошибок SEO для малого бизнеса: ответы, которые Вы ищете
SEO для малого бизнеса: ответы, которые Вы ищете Юзабилити аудит сайта
Юзабилити аудит сайта SEO продвижение сайтов
SEO продвижение сайтов