


Сьогодні хочу поговорити з вами про запобігання індексації від Googlebot для певних сторінок. Це необхідно для того аби приховати від пошукової системи сторінки, які не слід їй показувати, або ж навпаки показати, які сторінки слід індексувати.
Загалом є чотири правила, які забороняють індексацію певних сторінок:
- Robots.txt
- <meta name=”robots” content=”noindex,nofollow”>
- X-Robots-Tag noindex, nofollow
- Canonical
Як закрити індексацію сторінки від пошукових систем через Robots.txt?
Це основний файл, який Google шукає в першу чергу, тобто одразу після потрапляння на сайт. Саме він повинен повідомити пошуковій системі, куди їй можна чи не можна заходити. В першу чергу в ньому слід вказати весь контент, який ви плануєте приховати від пошукових систем.
До прикладу, на нашому сайті https://plerdy.com/robots.txt не було причин нічого закривати. У нас близько трьох сотень сторінок, проте немає потенційних дублів, фільтрацій, які потрібно було б закривати. Це більше необхідно для Інтернет-магазинів, наприклад, сайт https://www.foxtrot.com.ua/robots.txt має вже досить багато закритих сторінок, хоча багато є і дозволених. При цьому є моменти, особливо в таких CMS-системах, як magento та opencart, де є десятки рядків, які варто закривати.
Окрім цього Robots.txt допомагає, якщо у вас проблеми із сервером, а Googlebot пробує сканувати сторінки. В цьому випадку обов’язково закривайте Robots.txt і навантаження може впасти. Це, звісно, можна робити іншими способами.
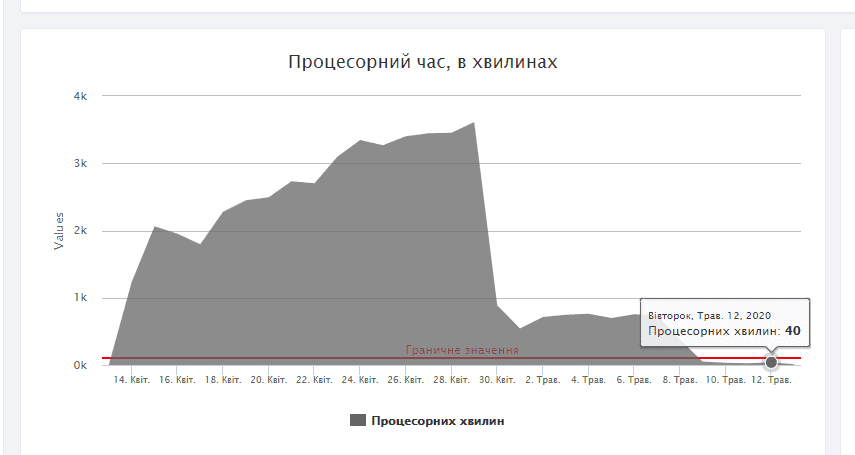
Я показую вам приклад, коли було зроблено зменшення кількості автоматичних запитів від Googlebot в день з 8 до 3. Це дозволило не індексувати зайві сторінки та розв’язати проблему.
Ви можете побачити, як налаштовувати сторінки Robots.txt тут.
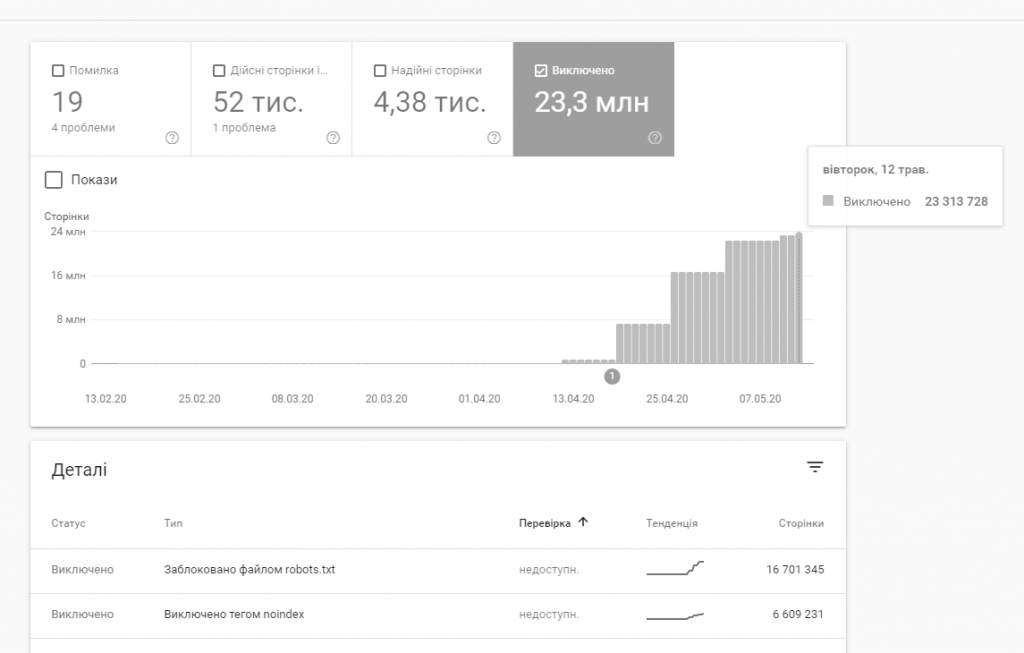
Це приклад, коли Googlebot робив спроби індексувати дуже багато сторінок. Частина із них закрита з допомогою Robots.txt, частина з noindex.
Як закрити індексацію сторінки від пошукових систем за допомогою <meta name=”robots” content=”noindex,nofollow”>
При використанні другого і третього способів закриття сторінок (<meta name=”robots” content=”noindex,nofollow”> та X-Robots-Tag noindex,nofollow) Googlebot змушений зайти на сторінку і лише після цього сказати, що не буде її індексувати.
Як закрити індексацію сторінки від пошукових систем за допомогою X-Robots-Tag noindex, nofollow
Третій спосіб не є ефективним для зменшення кількості індексації та запитів, тобто вони не з’являться у пошуку, але Google буде робити спроби зайти на них. Крім цього він є найбільш рідкісним, але Google його підтримує. Якщо говорити про мою особисту практику, то приблизно за 10 років, я використовував його всього один раз.
Canonical, як ще один спосіб боротьби із контентом, що дублюється
Якщо у вас є посилання з GET-параметрами й вони також є дублями, тоді слід ставити там Canonical. Якщо ж його поставити на звичайному посиланні, тоді Google може ігнорувати його та продовжувати індексацію. Таке трапляється доволі часто. Бажано таких моментів уникати, хоча критичного у цьому нічого немає.
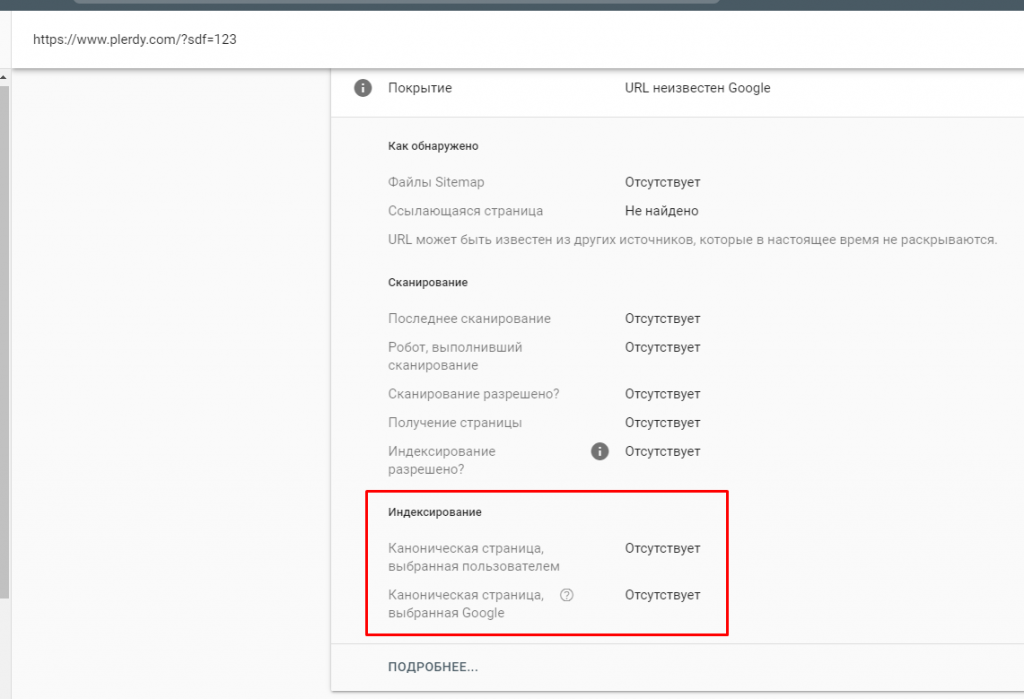
Як бачите на прикладі, якщо сторінка є не проіндексована, то Canonical показувати не буде. Тобто, вона мусить бути проіндексованою, щоб Google це побачив і це важливо.
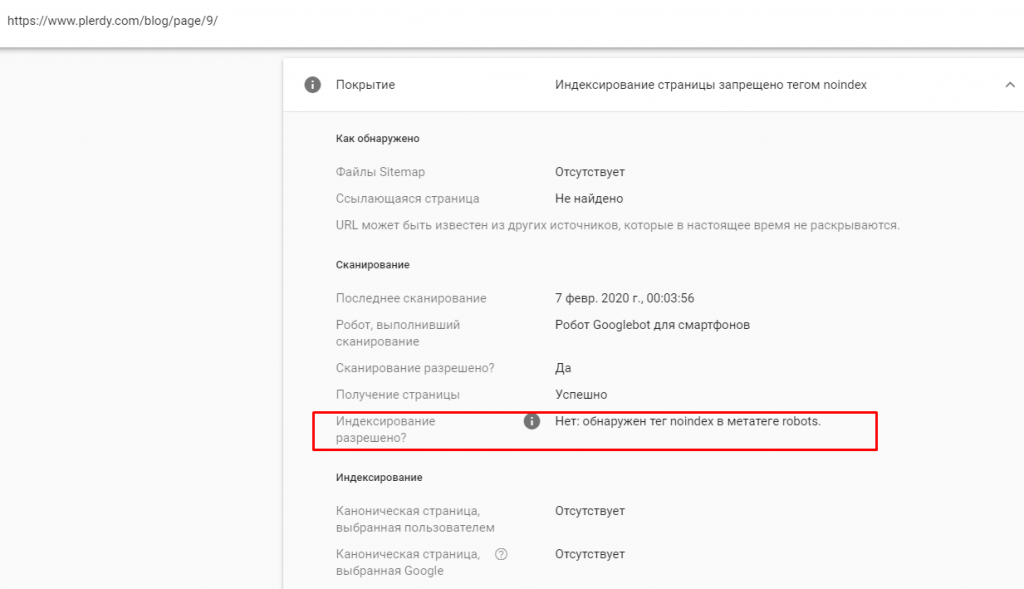
Ще один важливий момент – коли сторінка заблокована, вона буде давати дозвіл індексувати, але забороняти показувати її пошуковій системі. Якщо ж вона заблокована в Robots.txt, то в графі про дозвіл на індексацію буде стояти – ні.
Міксування цих способів закриття сторінко від індексації в пошукових системах
Слід уникати міксування усіх цих способів чи певних з них. Це не є строгою забороною і ви не отримаєте санкцій, але спеціалісти від Google кажуть, що варто все-таки уникати цього. Хоча я особисто бачив чимало прикладів, де все знаходиться на одній і тій самій сторінці.
Якщо ви хочете перевірити, додати певні посилання чи забрати, то для цього є тестування файлу Robots.txt. Там можна додати будь-яке правило, переглянути інструкцію та зробити усе правильно, щоб випадково не заблокувати сторінку, яка є потрібною. У цій інструкції вказано, що файл Robots.txt не є обов’язковим, але, на мою думку, він таки обов’язковий. Завдяки йому вирішується чимало питань, особливо, якщо мова про великі інтернет-магазини.
Ці основні правила, які я озвучив, обов’язково слід налаштовувати перед запуском сайту, а також слідкувати в процесі за усіма сторінками, щоб чітко розуміти, як і куди ходить Google.
Якщо у Вас виникли запитання, залишайте коментарі чи пишіть мені у соціальних мережах:
- https://www.instagram.com/andriy_chornyy/
- https://www.facebook.com/chornyy.a
Я з радістю Вам відповім та допоможу покращити конверсію Вашого інтернет-магазину.

 (2 оцінок, середнє: 3.00 з 5)
(2 оцінок, середнє: 3.00 з 5) Як вибрати петличний мікрофон?
Як вибрати петличний мікрофон? Що насправді відбувається за лаштунками успішного SEO-проєкту
Що насправді відбувається за лаштунками успішного SEO-проєкту Що насправді пишуть про ваш бренд: автоматизований контент аналіз як головна зброя PR-фахівця
Що насправді пишуть про ваш бренд: автоматизований контент аналіз як головна зброя PR-фахівця CRM для Binotel: як об’єднати телефонію, клієнтську історію та продажі в одній системі
CRM для Binotel: як об’єднати телефонію, клієнтську історію та продажі в одній системі Як створити природний лінкопрофіль за допомогою крауд-посилань
Як створити природний лінкопрофіль за допомогою крауд-посилань Карта кліків сайту: огляд 16 сервісів
Карта кліків сайту: огляд 16 сервісів Просування сайтів: 9 факторів
Просування сайтів: 9 факторів Розкрутка сайту в Google: 20 порад
Розкрутка сайту в Google: 20 порад Просування інтернет-магазину
Просування інтернет-магазину Просування сайту в ТОП-10 Google
Просування сайту в ТОП-10 Google