


Robots.txt – это простой текстовый файл, который играет очень важную роль в SEO. С помощью специальных указаний, которые в нем содержатся, можно управлять индексацией сайта поисковыми роботами. А точнее – позволять или запрещать индексацию отдельных страниц, категорий и сайта в целом.
В отличие от многих других вещей, которые касаются области поисковой оптимизации, здесь все четко и понятно – поисковые системы однозначно говорят о том, что данный файл должен быть на сайте, а в официальных справках содержится соответствующая информация по теме его настройки.
Находится файл robotx.txt в корневой папке сайта — это единственное место, в котором он может быть расположен. Это, кстати, позволяет легко посмотреть, как он выглядит на любом другом сайте – достаточно набрать в адресной строке браузера URL такого вида: http://yoursite.com/robots.txt
Важно знать, что в некоторых случаях, даже несмотря на наличие прямого указания относительно того, включать или не включать определенные данные с сайта в индекс, поисковые роботы могут проигнорировать его. Google подчеркивает, что информация из этого файла воспринимается исключительно как рекомендация, а не обязательный момент. Но на практике подобное бывает редко.
Для чего нужен robots.txt?
На любом сайте, кроме информации, предназначенной непосредственно для посетителей, присутствует и другой контент. Например, служебные страницы, автогенерируемые URL, изображения, скрипты и т. д. И далеко не все это владелец сайта хотел бы видеть доступным в поисковом индексе. Как я уже писал, именно для этого и используется данный файл – указать поисковым роботам, какие страницы нужно показывать в поиске, а какие нет.
Например, в robots.txt, который показан на скриншоте ниже, роботу Яндекса запрещено показывать в индексе страницы авторизации и регистрации WordPress, административную часть, вложения, страницы авторов и т. д.:

Директивы robots.txt
Файл имеет строго определенный синтаксис, и малейшая ошибка в символах делает строку, в которой она допущена, неработающей. Например, при указании основного зеркала сайта его адрес нужно прописывать без http:// и закрывающего слеша. Если сделать наоборот – это будет некорректно, а значит, она просто не будет работать.

Основные директивы, которые используются в robots.txt, одинаковы для всех роботов:
- User-agent – указания для конкретного робота (Google, Яндекс).
- Disallow – запрещает индексацию всего сайта или отдельной его части.
- Allow – разрешает выборочную индексацию отдельной части сайта.
- Host – позволяет указать главное зеркало сайта.
- Sitemap — указывает путь к файлу карты сайта.
- Clean-param – если на сайте есть адрес с динамическими параметрами, но одинаковым контентом, данная директива позволяет указать, что разные значения определенного параметра стоит воспринимать как один и тот же URL.
- Crawl-delay – позволяет указать диапазон времени между повторным посещением сайта роботом, что может быть продиктовано необходимостью снизить нагрузку на сервер.
Примеры использования
Итак, сами директивы мы перечислили, а теперь давайте рассмотрим их применение на практике. Смотрим примеры ниже.
Разрешить всем поисковым роботам доступ ко всему сайту:

Запретить индексацию всего сайта для всех поисковых роботов:

Разрешить доступ одному роботу (Яндекс) и запретить для всех остальных:

Запретить индексацию одной папки или конкретной страницы:
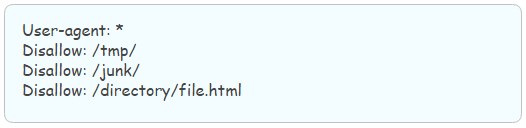
Запретить индексацию папки, но позволить индексировать конкретный документ, который в ней находится:

Есть и более сложные примеры директив. Например, с помощью следующей конструкции можно запретить поисковику индексировать страницы, которые содержат в своем URL знаки вопроса:

Обычно знаки вопроса содержатся в автогенерируемых страницах, которые выдаются CMS в ответ на какой-то запрос пользователя (поиск, фильтр), и на них дублируется основной контент. Таким образом, запрещая их индексацию, владелец сайта может избежать появления дублей в выдаче, а значит, и возможных санкций.
Директив для роботов в этом файле может быть очень много, как говорится, на все случаи жизни. Например, вот как выглядит robots.txt на известном сайте Ain.ua, который работает на базе WordPress:
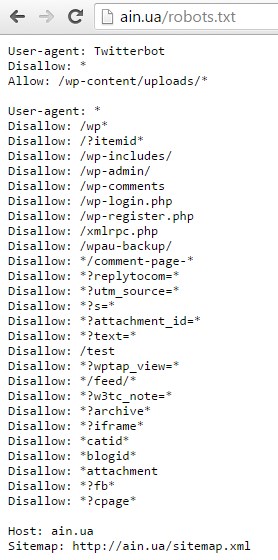
Как видите, список здесь немалый – 34 строки!
Что интересно, все эти настройки можно сделать с помощью специального плагина для WordPress — “Yoast SEO”, который сразу вставляет в код, активирует канонические адреса и избавляет от необходимости прописывать множество директив в самом файле.
Каким должен быть правильный robots.txt?
Содержимое файла robots.txt отличается в зависимости от типа сайта (интернет-магазин, блог), используемой CMS, особенностей структуры и ряда других факторов. Поэтому заниматься созданием данного файла для коммерческого сайта, особенно если речь идет о сложном проекте, должен SEO-специалист с достаточным опытом работы.
Неподготовленный человек, скорее всего, не сможет принять правильного решения относительно того, какую часть содержимого лучше закрыть от индексации, а какой позволить появляться в поисковой выдаче.
Например, вот как выглядит хороший robots.txt для сайта под управлением WordPress, ориентированного на продвижение в поисковых системах Google и Яндекс, который монетизируется с помощью Google AdSense:

Для сложного по структуре и высоконагруженного проекта, который работает на CMS Joomla:

А также для еще одного популярного движка – Drupal:

В целом можно вывести несколько правил, с учетом которых можно создать оптимальный robots.txt именно для вашего сайта:
- первой в списке всегда идет директива User-agent, потом – Disallow (менять их местами нельзя);
- инструкция Disallow должна присутствовать в файле обязательно, даже если вы не собираетесь ничего запрещать – в таком случае просто оставьте ее пустой;
- текст пишется только в нижнем регистре;
- текст нельзя переносить в новую строку;
- если нужно запретить индексацию папки, перед ее названием обязательно нужно поставить знак слеш «/»;
- в каждой директиве (disallow/allow) указывается только одна директория или файл.
Как проверить robots.txt на ошибки
Допустить ошибку случайно может даже опытный специалист просто из-за невнимательности в определенный момент работы. Что уж тут говорить о новичках, которые порой вместо того, чтобы открыть сайт для индексации, запрещают ее, а потом удивляются, почему так долго нет трафика с Google.
Таких примеров существует немало, поэтому, чтобы избежать подобных проблем, можно воспользоваться специальными инструментами для проверки robots.txt, которые предоставляют веб-мастерам сами поисковые системы.
В Google Search Console для того, чтобы убедиться в корректности данного файла, нужно перейти в раздел «Сканирование», нажать на него и выбрать в меню пункт «Инструмент проверки файла robots.txt»:

Как видно на приведенном примере, ошибок у нас нет. Для того чтобы выполнить аналогичную задачу в Яндекс.Вебмастер, необходимо в разделе «Инструменты» выбрать пункт «Анализ robots.txt» и выбрать нужный из списка проектов, добавленных вами в эту панель:

Вывод
Файл robots.txt – отличный инструмент для управления индексацией веб-проектов, предоставленный владельцам сайтов поисковыми системами. И для сложных проектов это настоящая панацея, ведь с его помощью можно «спрятать» от поисковых роботов все ненужное, при этом реализовав на сайте весь требуемый функционал.
Но необходимо иметь в виду, что, несмотря на кажущуюся простоту работы с данным файлом, даже одна маленькая ошибка в нем может причинить много вреда. Поэтому, если вы не уверены в своих знаниях, лучше не экспериментировать со сложными конструкциями и директивами, а обратиться за помощью к специалисту или просто открыть для индексации весь сайт.
- Автор: Владимир Федоричак

 (9 оценок, среднее: 4,44 из 5)
(9 оценок, среднее: 4,44 из 5) Карта кликов сайта: обзор 16 сервисов
Карта кликов сайта: обзор 16 сервисов Продвижение сайтов
Продвижение сайтов Бесплатная раскрутка сайта в Google: 20 советов
Бесплатная раскрутка сайта в Google: 20 советов Продвижение интернет-магазина
Продвижение интернет-магазина Продвижение сайта в ТОП-10 Google
Продвижение сайта в ТОП-10 Google Контекстная реклама сайта в Google: 27 ошибок
Контекстная реклама сайта в Google: 27 ошибок SEO для малого бизнеса: ответы, которые Вы ищете
SEO для малого бизнеса: ответы, которые Вы ищете Юзабилити аудит сайта
Юзабилити аудит сайта SEO продвижение сайтов
SEO продвижение сайтов SEO оптимизация интернет магазина
SEO оптимизация интернет магазина
Доброго дня, під скажіть будь ласка як правильно скласти роботс текст для платформи bloger, щоби пошуковий бот сканував переспрямування з http на https
бо при запиті на сканування сторінки пише переспрямовано
Доброго дня! Не вкурсі які там налаштування дозволені. Може це допоможе https://support.google.com/blogger/answer/6284029?hl=ru